The current digital age fundamentally changes how we as individuals and a society collect and distribute information. With these changes come powerful new approaches to influence the public agenda. However, the quality of shared information varies widely, and can have wide-reaching consequences. As the sophistication and accessibility of AI tools continue to expand, the authenticity of digital content has been increasingly called into question. Our team stands at the forefront of the challenge to safeguard digital space, as we assess the nature of content and how it proliferates online. For more information check out our a4.institute.
Selected Publications
A Guide to Misinformation Detection Datasets
Data is a barrier to reliable misinformation detection solutions. To address this, we curated the largest collection of (mis)information datasets in the literature, totaling 75. From these, we evaluated the quality of all of the 36 datasets that consist of statements or claims. We assessed these datasets to identify those with solid foundations for empirical work and those with flaws that could result in misleading results, such as insufficient label quality, spurious correlations, or political bias. We further show that regardless of label quality, categorical labels may no longer give an accurate evaluation of detection model performance, and discuss ways to solve this. Overall, this guide aims to provide a roadmap for obtaining higher quality data and conducting more effective evaluations in this domain.
A Simulation System Towards Solving Societal-Scale Manipulation
In this paper, we present a multi-agent simulator based on Deepmind’s Concordia, a software library for LLM-based multi-agent simulations of real world human experience. Our unique contribution is the addition of an online social media environment component as well as agent persona generation from measured psychological trait survey data. We demonstrate the simulator by simulating a 100-agent town election under different manipulation conditions. Through longitudinal surveys, we show via our custom dashboard the effects of manipulation in altering the outcome of elections.
Web Retrieval Agents for Evidence-Based Misinformation Detection
We demonstrated an effective two LLM agent architecture for misinformation detection and fact-checking. It can increase the macro F1 of misinformation detection by as much as 20 percent compared to LLMs without search. We also conducted extensive analyses on the sources our system leverages and their biases, decisions in the construction of the system like the search tool and the knowledge base, the type of evidence needed and its impact on the results, and other parts of the overall process.
An Evaluation of Language Models for Hyperpartisan Ideology Detection in Persian Twitter
While LLMs have demonstrated how effective they can be for tasks in the English language, such as detecting social media users’ political ideology, their performance in other languages remains understudied. We contribute to this area of research by fine-tuning smaller LLMs to identify hyperpartisans in Persian social media, and compare the results to those from open-source and commercial models.
Party Prediction for Twitter
Partisanship has increasingly become a major point of contention in public discourse online, and as a result, researchers have developed a variety of methods to evaluate the party affiliations of users on social media. In this paper, we evaluate the performance of party prediction tools and propose new methods that are comparable or improve upon existing works.
Towards Reliable Misinformation Mitigation: Generalization, Uncertainty, and GPT-4
We propose focusing on generalization, uncertainty, and how to leverage recent large language models, in order to create more practical tools to evaluate information veracity in contexts where perfect classification is impossible. This was one of the first works to study post-ChatGPT models in this domain. We first demonstrated they can outperform prior methods in multiple settings and languages, exhibit differences in failure modes, can quantify uncertainty, and other aspects of their usage. We also published the LIAR-New dataset with novel paired English and French misinformation data, and Possibility labels that indicate if there is sufficient context for veracity evaluation.
The Surprising Performance of Simple Baselines for Misinformation Detection
While many sophisticated detection models have been proposed in the literature, they were often compared with older NLP baselines such as SVMs, CNNs, and LSTMs. We showed that with basic fine-tuning, BERT-type language models were competitive with and could even significantly outperform state-of-the-art methods of the time. We further studied a comprehensive set of benchmark datasets, and discuss potential data leakage and the need for careful design of the experiments and understanding of datasets to account for confounding variables.
Technology Transfer
Veracity AI
![]()
This project combines large language models (LLMs) with web search APIs to create an AI-powered fact-checking tool. The goal is to develop a publicly accessible app that empowers individuals to verify the accuracy of information they encounter online. This app goes beyond fact-checking and aims to enhance the understanding of its users by offering credible sources.
Designed to be user-friendly and transparent, the app ensures that users can see the reasoning and evidence behind its conclusions. This combination of AI-powered analysis and credible source linking aims to build trust in the tool while addressing the growing challenges of misinformation and disinformation
Social Simulation
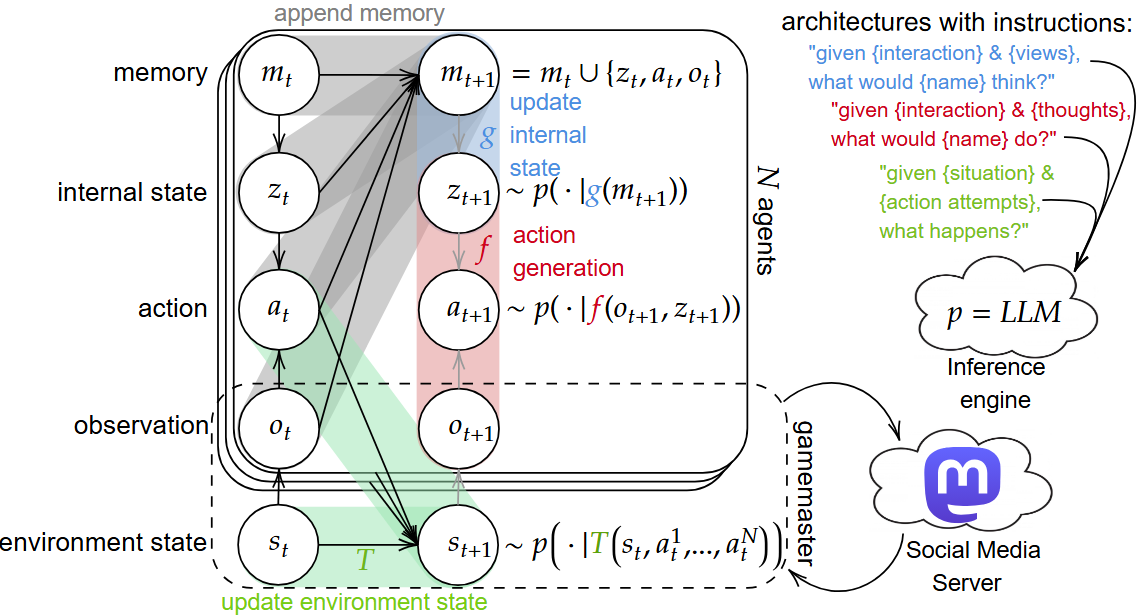 Multi-agent simulator based on Deepmind’s Concordia, a software library for LLM-based multi-agent simulations of real world human experience.
Multi-agent simulator based on Deepmind’s Concordia, a software library for LLM-based multi-agent simulations of real world human experience.
Funding
We acknowledge funding from the Canadian Institute for Advanced Research (CIFAR AI Chair Program), the Fonds de recherche du Québec – Société et culture (FRQSC), the Social Sciences and Humanities Research Council (SSHRC), Mila - Quebec AI Institute,the Government of Canada, UK Research and Innovation (UKRI), and IVADO (Institute for Data Valorization).